
Quasi un milione di buchi neri finti per capirne due veri
L'Event Horizon Telescope ha prodotto la prima immagine di un buco nero, ma leggerne i dati grezzi è un problema più sottile. Il buco nero non sta mai fermo.
In questo articolo
Immaginate di voler addestrare un programma a riconoscere i volti. Gli servono migliaia di foto: illuminate di giorno, di notte, di profilo, sfocate, con gli occhiali. Il programma impara a ignorare le variazioni irrilevanti e a estrarre i tratti che contano. Con i buchi neri il problema è lo stesso, tranne che nessuno sa esattamente che faccia abbiano. E la faccia cambia ogni pochi minuti.
L’Event Horizon Telescope (EHT), la rete di otto radiotelescopi sparsi per il pianeta che nel 2019 ha prodotto la prima immagine di un buco nero, raccoglie dati enormemente complessi. Non sono fotografie: sono misure di interferenza tra coppie di telescopi, pezzi sparsi di informazione che vanno ricostruiti. Un gruppo di ricerca guidato da Michael Janssen, in un articolo pubblicato su Astronomy & Astrophysics, ha costruito una libreria di quasi un milione di osservazioni simulate per addestrare una rete neurale a interpretare quei dati. La domanda che guida il lavoro non è “che aspetto ha il buco nero”, ma qualcosa di più sottile: come si insegna a un programma a riconoscere le proprietà fisiche di un oggetto che non ha mai lo stesso aspetto due volte?
Il campo di addestramento più realistico mai costruito
Per addestrare una rete neurale servono esempi etichettati. Nel caso dell’EHT, ogni esempio è un’osservazione simulata di un buco nero con proprietà note: quanto ruota, quanto è magnetizzato il disco di materia che lo circonda, da che angolo lo vediamo. La rete impara ad associare certi schemi nei dati a certi valori di questi parametri, e poi li applica ai dati reali.
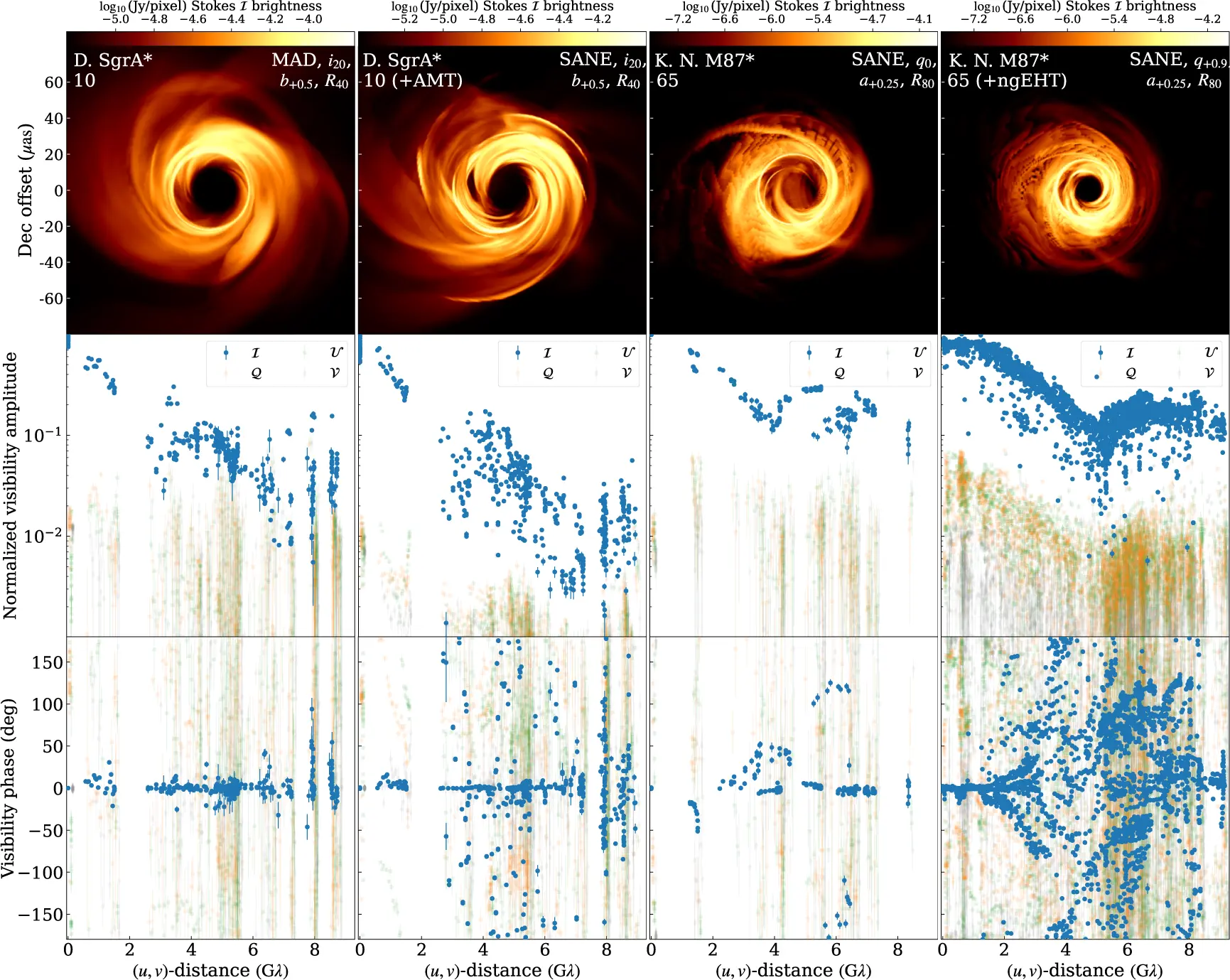
Il problema è che simulare un’osservazione EHT non significa prendere un’immagine teorica e aggiungere un po’ di rumore. Significa riprodurre l’intero percorso del segnale: la turbolenza atmosferica sopra ogni telescopio, gli errori di puntamento delle antenne, il vapore acqueo nei cieli del Cile e delle Hawaii, la perdita di sensibilità quando l’atmosfera cambia più velocemente di quanto il software di correzione riesca a seguire. Janssen e colleghi hanno simulato tutto questo per due bersagli, i buchi neri supermassicci Sagittarius A* (Sgr A*) al centro della Via Lattea e Messier 87 (M87*), producendo 600 000 dataset sintetici per M87* e 252 000 per Sgr A*. In totale, 962 000 osservazioni finte con etichette vere.
Il realismo della simulazione è il punto chiave. I dati sintetici passano attraverso lo stesso software di calibrazione usato per i dati reali, con gli stessi difetti e le stesse correzioni. Se il programma di calibrazione introduce un artefatto nei dati veri, lo introduce anche in quelli sintetici. La rete neurale li vede entrambi e impara a non confonderli con segnali fisici.
Quando il nemico è il buco nero stesso
La calibrazione dei telescopi è migliorata. Gli autori hanno aggiornato il software di riduzione dati dell’EHT, combinando bande di frequenza e canali di polarizzazione in modo più efficiente. Il risultato è un aumento del 10 per cento nella sensibilità delle misure su tutte le coppie di telescopi, soprattutto per i segnali più deboli. In termini pratici, il nuovo metodo riesce a “vedere” connessioni tra telescopi che prima andavano perse. È un progresso tecnico solido.
Ma il problema principale nel ricavare le proprietà fisiche del buco nero dalle misure non è il rumore strumentale, ma quanto i buchi neri cambiano nel tempo.
Sgr A* è un caso estremo. La materia in caduta verso il buco nero al centro della nostra galassia cambia configurazione su scale di minuti, perché il buco nero ha una massa “piccola” per gli standard dei buchi neri supermassicci: circa quattro milioni di volte quella del Sole. Il tempo caratteristico delle fluttuazioni è di circa 20 secondi. Una singola osservazione EHT dura 12 ore. In quel periodo il buco nero cambia aspetto centinaia di volte. Per simulare una sola osservazione di Sgr A* servono 432 fotogrammi consecutivi della simulazione.
M87* è più stabile, con un tempo caratteristico di otto ore, perché è 1500 volte più massiccio. Un singolo fotogramma basta per un’intera osservazione simulata. La stabilità però è relativa: su scale di mesi e anni, anche M87* cambia, e capire quanto cambia è una delle chiavi per distinguere i modelli.
La foto che mente
Il risultato più istruttivo del paper riguarda un modello specifico di Sgr A*: un buco nero con rotazione intermedia, disco fortemente magnetizzato, visto quasi di faccia. Questo modello, confrontato con i dati EHT del 2017 in modo statico, supera tutti i criteri di selezione usati dalla collaborazione EHT nelle analisi precedenti. Sembra un candidato plausibile.
Poi gli autori guardano la variabilità nel tempo. Generano tre realizzazioni sintetiche dello stesso modello sull’arco di un’intera sessione osservativa, ciascuna partendo da un fotogramma diverso della simulazione, e le confrontano con le misure reali. Il confronto avviene sulle fasi di chiusura: valori costruiti combinando i dati di tre telescopi in modo da cancellare gran parte degli errori strumentali. Su alcune triplette di stazioni il modello riproduce bene i dati. Su altre, dopo mezzogiorno, simulazione e realtà divergono nettamente.
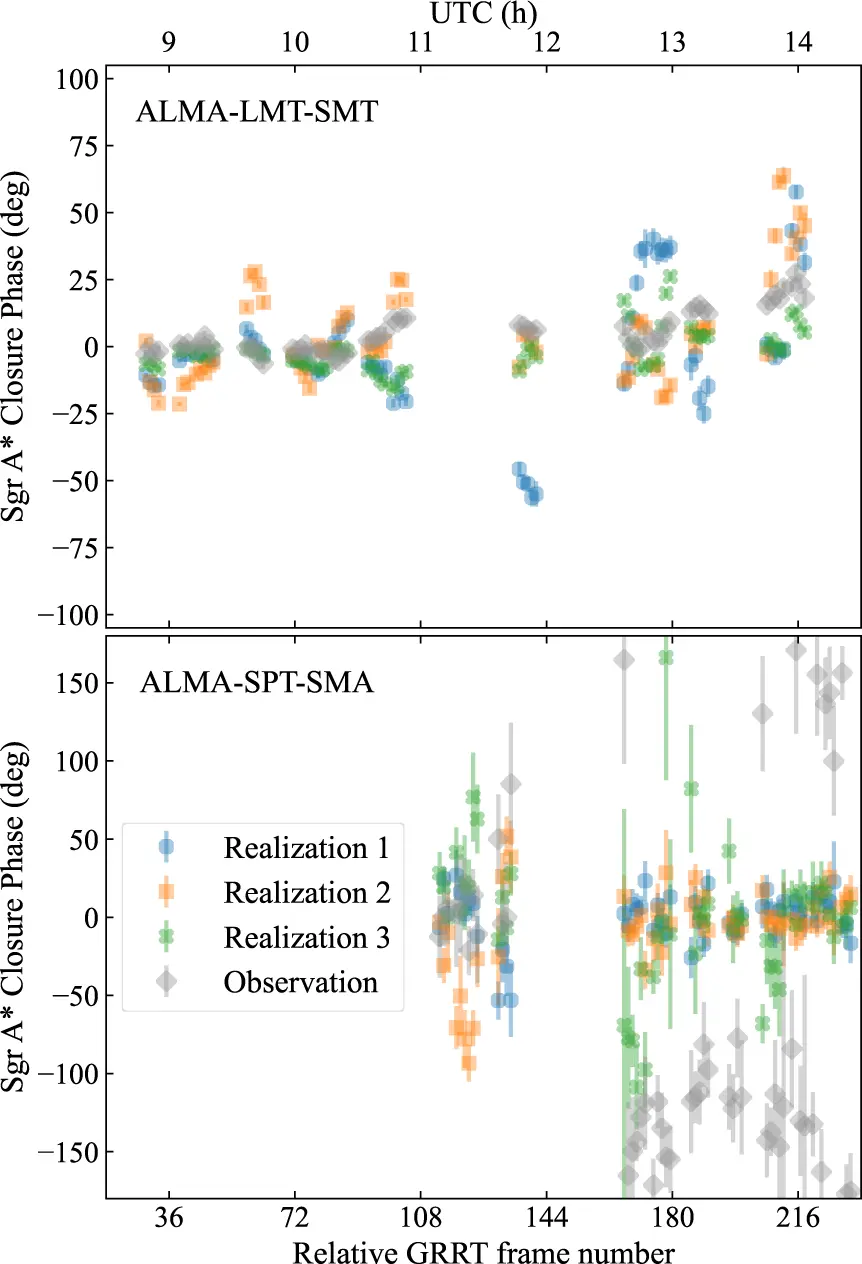
Una fotografia del modello sembrava giusta, ma il film no.
I modelli che aspettano un telescopio migliore
I modelli simulati coprono uno spazio di parametri ampio. Gli autori hanno incluso buchi neri standard descritti dalla relatività generale e due classi di buchi neri “esotici”: quelli con carica elettrica e i buchi neri dilatonici, previsti da certe varianti della teoria delle stringhe in cui la gravità si comporta diversamente vicino all’orizzonte.
Per i modelli standard, il comportamento è prevedibile: i dischi fortemente magnetizzati sono più turbolenti di quelli debolmente magnetizzati. Eruzioni di campo magnetico producono variazioni violente nella luminosità. I modelli dilatonici sono un caso a parte: non ruotano e non raggiungono mai lo stato di forte magnetizzazione, e un confronto sistematico della loro variabilità è rimandato a lavori futuri.
Per i buchi neri con carica elettrica, il segnale diagnostico è più diretto. Una carica sufficientemente alta riduce la dimensione dell’orizzonte degli eventi. L’ombra del buco nero si restringe, e questa riduzione lascia un’impronta nel segnale interferometrico: per rilevarla servono telescopi abbastanza distanti tra loro. Con la rete prevista dal progetto EHT di nuova generazione (ngEHT), che porterà le stazioni a 22, la differenza diventerebbe misurabile.
Cosa la rete deve imparare a ignorare
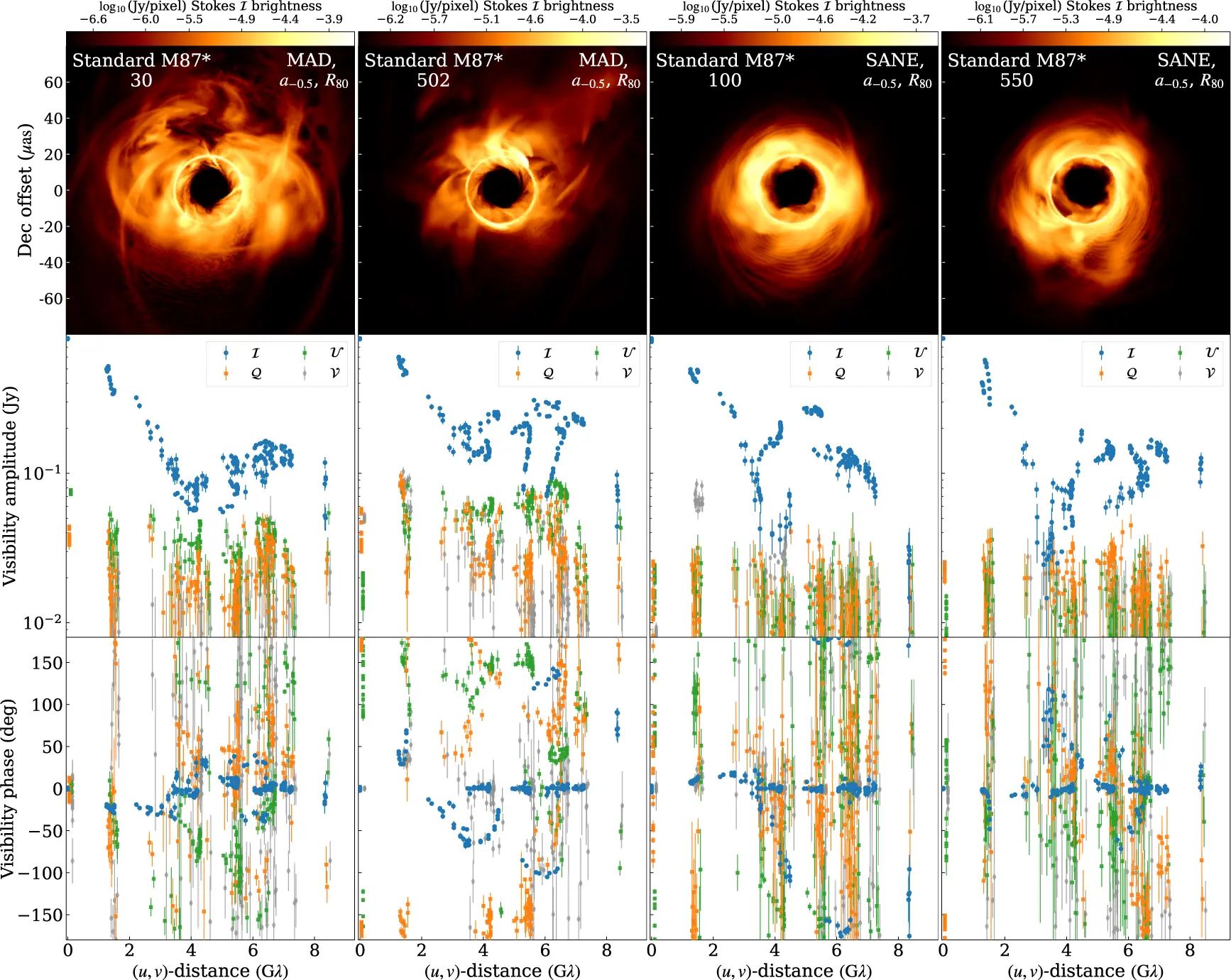
Il confronto diretto tra dati sintetici e modello teorico “perfetto”, riportato nell’appendice del paper, rivela dove si annida il rumore strumentale residuo. Le ampiezze del segnale in intensità totale sono ridotte dalle variazioni di sensibilità dei singoli telescopi e dagli errori di puntamento. La polarizzazione lineare è contaminata dal passaggio accidentale di segnale tra i canali: il dato sintetico mostra più polarizzazione di quella reale, perché lo strumento ne crea di artificiale. La polarizzazione circolare è quasi interamente un artefatto strumentale.
Le fasi di chiusura, quantità che combinano i dati di tre telescopi in modo da cancellare molti errori strumentali, sono invece stabili. La differenza tra il dato sintetico e il modello perfetto è minima. Questo le rende il prodotto più affidabile per l’inferenza dei parametri, e probabilmente il canale su cui la rete neurale farà più affidamento.
Le fasi di chiusura portano quasi solo segnale fisico: le ampiezze sono già più rumorose, e la polarizzazione circolare è quasi interamente artefatto strumentale. Una rete neurale addestrata su dati sintetici realistici può, in principio, imparare questa gerarchia da sola. Se i dati sintetici non fossero realistici, la rete imparerebbe una gerarchia sbagliata e poi fallirebbe sui dati veri.
Perché una sola notte non basta
Il paper dedica una sezione alla capacità di distinguere modelli diversi di M87* attraverso il monitoraggio a lungo termine. Tre modelli con parametri diversi producono fasi di chiusura che, su una singola osservazione, si sovrappongono. Su anni di osservazioni, i due modelli fortemente magnetizzati si separano da quello debolmente magnetizzato per il grado di variabilità. I due modelli fortemente magnetizzati si distinguono tra loro per il valore mediano della fase di chiusura, che dipende dalla velocità di rotazione del buco nero.
Nessuna singola osservazione basta: per separare i modelli serve il film, non la fotografia. E una rete neurale addestrata sull’intero arco di variabilità dei modelli può, in linea di principio, estrarre queste differenze anche da dataset singoli, perché ha visto abbastanza esempi da riconoscere le tracce della variabilità anche in uno “scatto” isolato. Gli autori anticipano che nei paper successivi della serie la rete neurale riesce a farlo: un modello addestrato sulla prima metà delle osservazioni predice correttamente i parametri della seconda metà.
Lo spazio tra il dato e la risposta
Questo paper è il primo di una serie di tre. Non contiene ancora l’inferenza vera e propria, quella che dirà «il buco nero ha questa rotazione con questa probabilità». Contiene il campo di addestramento, le regole del gioco, e le prime intuizioni su cosa funziona e cosa no.
La scelta di costruire quasi un milione di dataset sintetici che riproducono fedelmente il percorso del segnale, gli errori strumentali, e la calibrazione è un investimento pesante. Circa 100 gigabyte di dati per ciascuna sorgente. La giustificazione è semplice: una rete neurale è buona quanto i suoi dati di addestramento, e per i dati EHT non esistono scorciatoie. Il buco nero cambia faccia. L’atmosfera cambia. I telescopi sbagliano in modi diversi ogni notte. Se il campo di addestramento non cattura tutto questo, la rete impara un mondo semplificato e poi si scontra con la realtà.
Resta una domanda che il paper non affronta, perché spetta ai successivi nella serie: quanto è robusto il risultato quando il buco nero reale non corrisponde a nessuno dei modelli nel campo di addestramento? Lo spazio dei parametri è ampio, ma non infinito. La relatività generale prevede buchi neri descritti da massa, rotazione e carica. Se la gravità funziona diversamente vicino all’orizzonte degli eventi, i modelli nel campo di addestramento potrebbero non contenere la risposta giusta. La rete, in quel caso, darebbe comunque una risposta.
Riferimenti
Janssen, M. et al. (2025), Deep learning inference with the Event Horizon Telescope. I. Calibration improvements and a comprehensive synthetic data library, A&A, 698, A60. DOI: 10.1051/0004-6361/202553784