
The program that looks for Earths without seeing them
Finding an Earth-like planet takes years of observations and a lot of luck. One research group took a detour: score planetary systems first, then decide where telescope time is worth spending.
Finding an Earth-like planet, small and cool enough to allow liquid water on its surface, is one of the most expensive things you can ask a telescope to do. Planets are not necessarily rare. The problem is that they are small, far enough from their star to orbit slowly, and therefore hard to catch. If you pass in front of your star once a year, whoever is watching has to wait years just to understand that you exist.
The paper by Davoult, Eltschinger and Alibert, published in Astronomy & Astrophysics, starts from this frustration. The next missions designed for this work, such as PLAnetary Transits and Oscillations of stars (PLATO), a European space telescope dedicated to planetary transits and stellar oscillations, and the Large Interferometer For Exoplanets (LIFE) concept, a future network of space telescopes for observing planets directly in infrared light, will still have limited time. Every star observed for a long time is a bet.
So the authors asked a program to act as a bookmaker. There is no photograph of a second Earth here. The task is indirect: look at the planets we already know in a system, their mass, their distance from the star, the way they are arranged, and try to say whether a hidden Earth-like planet could be there.
The idea is elegant because it uses the architecture of the planetary system as a clue. It is risky because the program learns on fake systems.
The family says something about the missing planet
In the paper, an Earth-like planet means something measurable rather than a strong claim of habitability: a rocky planet with a mass between 0.5 and 3 Earth masses, in the temperate zone of its star, meaning an equilibrium temperature between 160 and 510 kelvin. It is a broad definition, broader than the classic habitable zone. The authors write that extending the target zone increases the number of positive systems and reduces data imbalance, which helps the model.
Astronomers know almost 5 000 planetary systems, according to the count the authors used in July 2024. But with that definition, only 24 systems host at least one Earth-like planet. Half a percent. Too few to train any machine learning model, a program that learns regularities from examples.
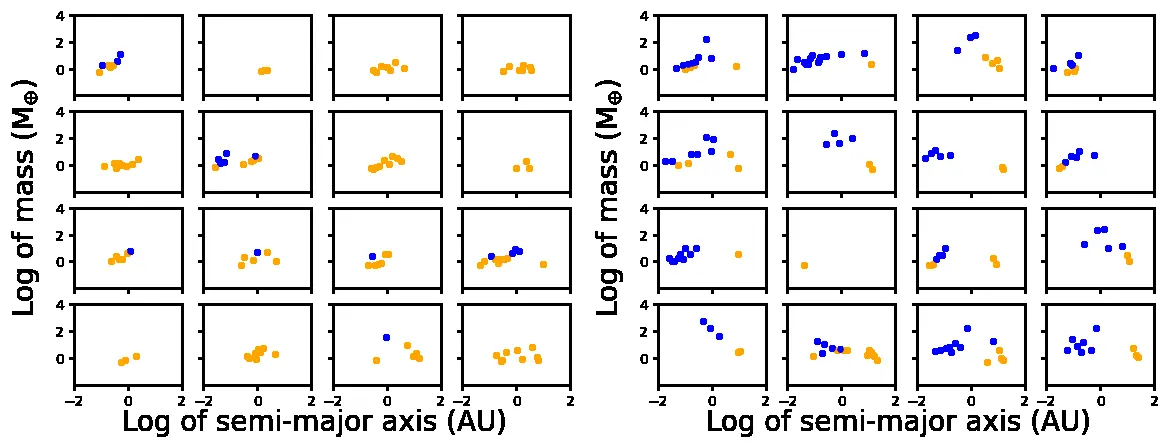
The Bern model solves that problem in a peculiar way: it is a simulation of planetary formation that builds complete systems starting from disks of gas and dust around young stars. In each synthetic system, everything is known, including the planets that in reality would be too small, too cold, or too slow to be discovered. It is like having a complete catalogue of planetary families, including the members a real telescope would miss.
The authors used three populations of synthetic systems: 24 365 around stars similar to the Sun, 14 559 around stars with half the Sun’s mass and 14 958 around stars with one fifth of the Sun’s mass. Then they did the necessary thing: they pretended to observe those systems with the limits of our instruments. The planets too faint to detect disappear from the catalogue. Only the ones that, in a real search, we would have some chance of seeing remain.
This step is the heart of the work. In reality, we observe the damaged version of the truth: a few visible planets, many hidden planets and the question of whether one of the hidden ones is Earth-like. The training set has to mimic that incomplete view.
The signal is the architecture
The word “architecture” sounds decorative, but here it is concrete. It describes how the planets are arranged in a system: how many are visible, how massive they are, whether masses grow or shrink as you move outward, whether there is a giant planet, whether the innermost visible planet is small or large.
A planetary system has a shared history. Planets are born in the same disk and affect one another while they migrate, collide, steal gas, clear regions of the disk, or get ejected. That is why the presence of one planet can say something about the others. It is a clue.
The program used by the authors is a random forest, a “forest” of 500 small classifiers called decision trees. Each tree looks at some data and votes yes or no: according to it, the system hosts an Earth-like planet or it does not. The final answer depends on the majority, but the authors require more than 50 percent plus one. They use stricter thresholds: 70, 80, and 90 percent. If 9 trees out of 10 vote yes, the prediction is more reliable, but the price is that many good systems get discarded.
This choice turns the model into a filter for a short target list with stricter confidence. With limited telescope time, a false positive is expensive: you observe for years a star that had nothing to give. A false negative is different. You may lose a good target, but the sky has many possible targets. If you have to choose, you prefer a short, clean list.
The program learns from a few observable properties. The most informative one is the architecture of the system. Then come the mass and period of the innermost visible planet, where “period” means the time it takes to orbit the star once. In the Bern model, systems with an Earth often have few detectable planets, most of them small. When the visible catalogue contains many planets, especially massive or giant ones, it looks more like the model’s systems without an Earth.
The signal is a trace of formation history. A system dominated by small planets may have left room for a temperate terrestrial planet. A system with giants or with very close-in planets may have gone through more violent migrations, enough to empty or disturb the region where an Earth could survive.
The easy test was the fake one
On synthetic systems, the program does very well. With the voting threshold at 90 percent, precision reaches up to 0.99. In practice, among the systems the program labels as positive, almost all really contain at least one Earth-like planet.
But that number has to be read without getting hypnotised by it. That 0.99 lives inside the world of the Bern model. The training systems and the test systems are different, so the program is being tested on fresh examples. They still come from the same simulated physics, with the same compromises and the same defects. It is a serious exam, but taken in the same school where the program studied.
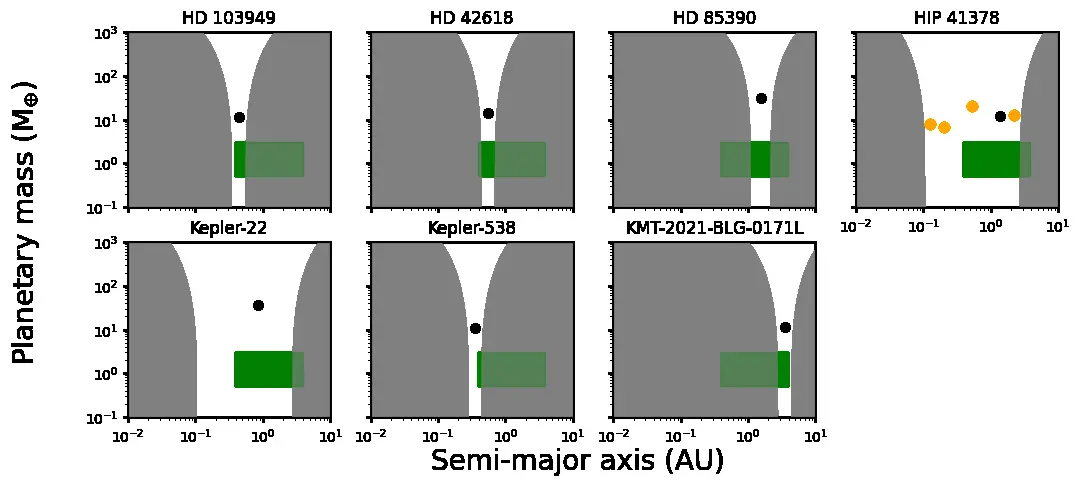
The jump to real systems is more delicate. The authors take 1 567 observed systems, all with at least one known planet and with the minimum information needed: planet mass, stellar mass and either distance or orbital period. The program assigns each one a vote. 51 systems pass the 90 percent threshold. After removing binary systems, because the Bern model used here simulates single stars and double stars complicate the temperate zone, 44 remain.
44 addresses where a hidden Earth might be worth looking for.
The list has names familiar to people who follow exoplanets: Kepler 22, LHS 1140, GJ 357, GJ 581, Teegarden’s star and Wolf 1061. The prediction says something narrower than “there is an Earth-like planet here”: according to a regularity learned from synthetic systems, the visible architecture of those systems resembles the architecture of systems that contain an Earth in the model.
The authors also do a simple dynamical check: if we added an Earth-like planet in the predicted region, would the system remain stable, or would it be wrecked by the orbits of the planets we already know? The answer is almost always reassuring. 95.5 percent of the 44 systems would remain stable with an added planet. Two cases are exceptions or require more caution: HIP 41378 among Sun-like stars and GJ 273 among the smallest red dwarfs, stars that are cool and low-mass.
Did the program learn the sky or the simulator?
The real question arrives only now. If the program gets synthetic systems right and selects 44 plausible real systems, what has it learned?
The honest answer is uncomfortable: it has learned the Bern model. If the Bern model reproduces the architectures of real systems well, then the list of 44 is valuable. If the model gets the correlations that matter wrong, the list becomes a test of the simulator more than a guide to planet hunting.
The authors say this clearly. The synthetic populations of the Bern model resemble real systems in some system-level properties: relations between inner planets and outer giants, mass distributions and similarities between neighbouring planets. They remain imperfect copies of the sky. They produce too many planets per system, at least 1.7 times more than observations indicate. They tend to put planets too close to the star. They have too many resonant configurations, meaning orbits in which planetary periods sit in simple ratios such as 2 to 1 or 3 to 2.
Here the paper changes nature. The program becomes a bridge between a simulation and the real sky. If a future telescope searched the 44 systems and found Earth-like planets, that would be an observational success and a point in favour of the Bern model. A null result would also be information: it would mean the simulator learned a planetary grammar different from the sky’s.
The machine learning prediction also becomes a test of the theory behind the simulator.
When absence becomes data
The best part of the paper is that failure would be useful. In many artificial intelligence applications, a false positive is just junk: the program said yes, reality said no, done. Here an observational no would have scientific value, because it would force the question of which correlation was false.
Maybe systems with few visible planets are less favourable than they look in the model. Maybe giants disturb less, or more, than the simulation suggests. Maybe the observational threshold used to imitate our instruments is too simple: the authors treat detectability mostly as a radial velocity problem, meaning the small motion a planet induces in its star, but in reality stellar activity, observing cadence, orbital inclination and other planets already in the system also matter.
Davoult and colleagues leave those limits on the table. The list of 44 systems is useful only if someone goes and checks it, telescope time and all.
This separates it from many works where machine learning is presented as a shortcut. Here the shortcut depends on a heavy assumption: that synthetic worlds are similar enough to real worlds. The precision of 0.99 does not solve the problem, because it measures how well the program understands its own training universe. The sky still has to vote.
Still, the idea is powerful. Searching blindly for Earth-like planets is slow. Searching only where a model says “there is room here, the planetary family looks like the right ones, an added planet would remain stable here” is a smarter strategy, even if it is fragile. The strongest result would be a system-by-system map of where the theory of planetary formation holds and where it breaks.
A second Earth, if it exists, does not send a signal saying “I am here”. Maybe it leaves only an imprint in the arrangement of the planets we have already managed to see. The program by Davoult and colleagues tries to read that imprint. It does not yet know whether it is reading the sky or the handwriting of the simulator.
References
Davoult, J., Eltschinger, R. and Alibert, Y. (2025), Earth-like planet predictor: A machine learning approach, A&A, 696, A94. DOI: 10.1051/0004-6361/202452434