
The network was looking for one thing, it found a thousand others
Hubble has been in orbit for over 30 years and has piled up 100 million images that nobody has ever really looked at. A neural network took two and a half days, and what it found was not what it was looking for.
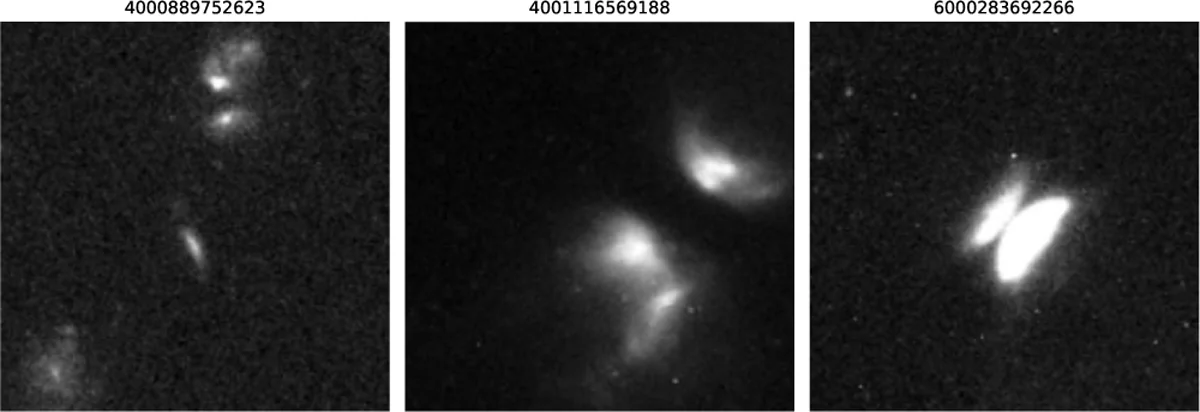
There are 43 objects in the archive of the Hubble Space Telescope (HST) that nobody knows what they are. They have been sitting in there for years, some for decades. Their shapes do not fit any known category. They might not be galaxies. They might not be anything astronomers have words for. They were dug up in late 2025 by a neural network that, as it happens, was looking for something completely different.
The Hubble archive holds nearly 100 million images of astronomical sources. Over 30 years of observations, taken one at a time by astronomers who asked the telescope for time to study a specific object. When the observation was done, the target got the spotlight. Everything else, the background, went into the archive and stayed there. This paper by O’Ryan and Gómez, published in Astronomy & Astrophysics, is about what happens when you try to look at that everything else, systematically, with a program. The story is mostly about how a neural network behaves when you ask it to find “something weird” without specifying too much what that means.
The problem of teaching a network what is rare
A neural network learns from examples. Show it a thousand pictures of cats and a thousand of dogs, and after a while it can tell them apart. This works as long as you have examples to spare.
In astronomy, you usually do not. Rare objects are rare by definition: a gravitational lens, an edge-on protoplanetary disk, a jellyfish galaxy trailing a veil of gas behind it. For some of these, only a few hundred are known in the entire sky. Trying to train a program with so few examples does not work: the network memorises the objects you showed it and falls apart on any variant.
There is a subtler problem too. To teach a network what is anomalous, you need to define what is normal first. But “normal” in the Hubble archive is a slippery thing. The images are grainy, overexposed, full of foreground stars, satellite trails, cosmic rays. An ordinary galaxy sits next to artefacts that an inexperienced eye would already find interesting.
O’Ryan and Gómez used an approach called semi-supervised learning, a term that describes a precise situation: you have very few hand-labelled examples and a flood of unlabelled data. The tool, AnomalyMatch, is a network that learns from both at once: from the few labelled examples it learns what to look for, from the flood of unlabelled data it learns what is ordinary. Plus a variant called active learning: the network proposes its best candidates, the author looks, confirms or rejects, and the model updates. A dialogue between program and human, in which the human does the work the network cannot do and the network does the work the human would never have time for.
The starting point was absurdly small. Three training images (in technical jargon, the training set: the data on which the network gets its eye in). Three. All of edge-on protoplanetary disks, which are young stars surrounded by a ring of dust and gas where planets are forming, seen perfectly side-on. The geometry produces a very distinctive butterfly shape: a dark dust lane across the middle, with light spilling out into two perpendicular lobes on either side. O’Ryan wanted to find more of these. They were the subject of his thesis.
What the network found by looking elsewhere
Three training images, 99.6 million cutouts to sift through. AnomalyMatch ran on ESA Datalabs, the European Space Agency’s science platform, for two and a half days, on a cluster of graphics cards dedicated to parallel computation (graphics processing units, or GPUs, the hardware neural networks now use instead of the CPU to crunch many data points at once).
The output is a list of 5 000 candidates ranked by an “anomaly score”, a number between 0 and 1 that says how far the network thinks a given image is from ordinary. After removing duplicates (the same object often appears in Hubble multiple times, with small offsets), 1 339 unique objects remain.
Of edge-on protoplanetary disks, the very thing they were looking for, only two came out. The reason is a footnote that says a lot: the archive they searched had been pre-selected in a single filter, a specific band of wavelengths of light. Edge-on protoplanetary disks are easier to spot in other bands, and most of those known to astronomers have been observed elsewhere. The network was looking in the wrong place.
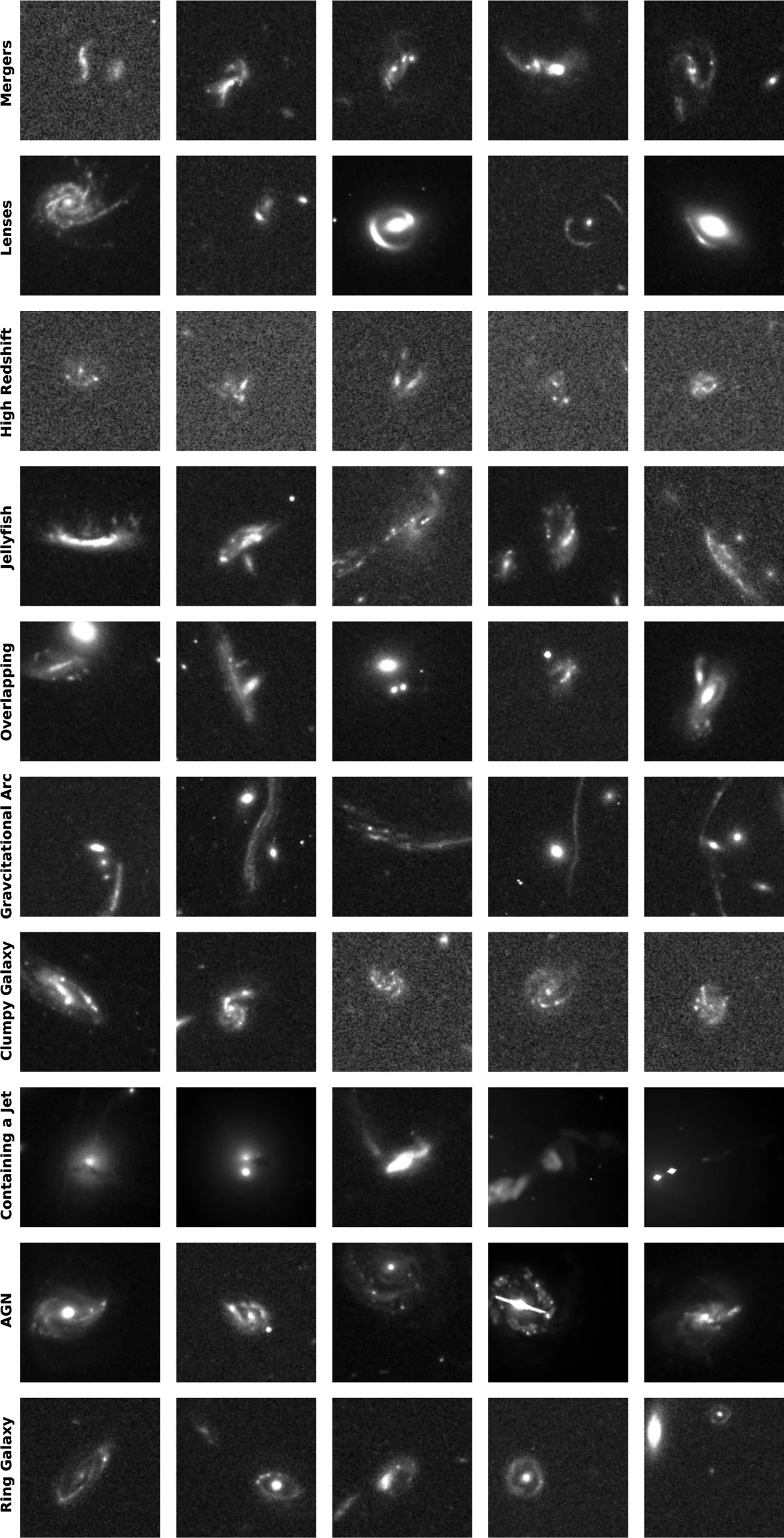
What it found elsewhere is the interesting part. More than half the sample (629 objects) are pairs of galaxies in the act of colliding, galactic mergers caught mid-passage. Then there are 140 candidate gravitational lenses, where the light of a very distant galaxy, travelling towards us, has been bent by the gravity of a foreground galaxy into a luminous arc or a ring: of these, more than half were not in any previous catalogue. And 35 jellyfish galaxies, objects that, while crossing through a galaxy cluster, get stripped of their gas by the pressure of the intergalactic medium and trail a wake of luminous tendrils behind them.
The number that matters is another: 811 of the 1 339 objects had no prior reference in the literature. 65 percent. A network that started from three examples picked out, in two and a half days, 800 objects that were sitting in the archive of one of the most studied telescopes in history and had never been described.
When the network learns what it does not know it knows
The most interesting detail in the paper is not how many objects the network found, but what it found without anyone teaching it to look for them. Among the 1 339 anomalies are five lensed quasars. A quasar is the very bright nucleus of a very distant galaxy, fed by a black hole devouring gas. When its light, travelling to us, gets bent by the gravity of an intervening galaxy, we call it a lensed quasar. The effect produces a characteristic image: four bright points arranged in a cross around the central galaxy, or two mirrored points. When there are four, it is called an Einstein cross. These are extremely rare objects, fewer than 200 are known across the whole sky.
AnomalyMatch found five of them. All previously known to astronomers, true, but here is what changes everything: there were no lensed quasars in the training set. Not one. The network had been trained on protoplanetary disks, on odd galaxies, on mergers and on a handful of plain lenses. One lensed quasar showed up on its own among the highest-scoring candidates. The authors then added one example to the training set, and the network turned up four more. Five total.
The network had learned a more abstract concept, something like “this image is strange”, solid enough to capture a class of objects of which it had never seen a single example. That is the kind of generalisation that makes neural networks useful beyond the tasks you set them up for, and that at the same time makes it hard to know what they are actually doing.
The authors tried to look inside the box with a method called SHAP, a system that produces heat maps: red pixels where the program leaned more heavily to assign its score, blue pixels where it looked less. On the lenses, the red sits on the gravitational arc. On the mergers, on the tidal tails, the bridges of stars and gas the two galaxies pull out of each other. On the edge-on disks, on the butterfly shape. It works as you would expect. For the Einstein cross, those maps are not shown, and the very fact that the network reached for an out-of-distribution object leaves a margin of mystery about what it actually saw.
The limits the network could not work around
AnomalyMatch produced 5 000 candidates. Those 5 000 candidates were looked through, one by one, by a single person: David O’Ryan, the first author, classifying them by hand based on morphology and looking each one up in existing astronomical catalogues.
This is the structural limit of this kind of work. The network gives you a ranking, not a discovery. To turn a ranking into a discovery you need someone who verifies each candidate, compares it with the literature, and decides what it is. In this case that someone was one person. In the next few years, with the Euclid mission (a European space telescope launched in 2023 to map billions of galaxies) churning out terabytes of data every night, and with the Vera C. Rubin Observatory now in operation, imaging the entire southern sky every three nights or so, the bottleneck will not be the network. It will be the human who has to look at what the network has flagged. The contamination rate of AnomalyMatch, the fraction of images flagged as anomalous that to a trained eye are normal, is about 10 percent. Filtering them out takes exactly the kind of trained eye the work was meant to spare.
Then there is something that has nothing to do with neural networks at all, and that on its own says why papers like this are interesting. The authors note that jellyfish galaxies may have been hard to pull in. The reason is neither astronomical nor algorithmic: the Hubble archive images had been saved as one-channel greyscale JPEGs, a format that aggressively compresses low-brightness pixels to save space. The tendrils of jellyfish galaxies, made of tenuous gas stripped from the host galaxy, live exactly in those low-brightness regions. More than a limit of the network, this is a limit of the source material: a compression compromise made who knows when may have erased upfront the very structures that would have made these objects recognisable. 30 years of astronomical data, and what we can find in them today is partly determined by a file-format choice that nobody thought would become a constraint.
100 million images, and starting again
65 percent of objects with no associated literature, in an archive astronomers have been consulting for decades, is a number that says something uncomfortable. Not about the telescope, which did its job. About our ability to look at what we already have. Astronomical observations are almost always taken by asking the telescope for time to point at a specific object. Whatever happens to be in the same field of view, next to the target, rarely gets examined. And so the discoveries pile up in the archive, waiting for a method that can fish them out.
AnomalyMatch is a version of that method, and there have been many over the years. What makes this paper notable is the combination of scale (the entire archive, not a subset), speed (two and a half days), and training-data efficiency (a few hundred labels in total). It is not a spectacular network from an architectural standpoint. It is an EfficientNet, a convolutional neural network: small filters that slide across an image and respond wherever they find local shapes, first edges and textures, then increasingly complex structures. On top of it there is the semi-supervised trick. The point is not how sophisticated the network is: it is that it works well enough to make practicable something that previously was not.
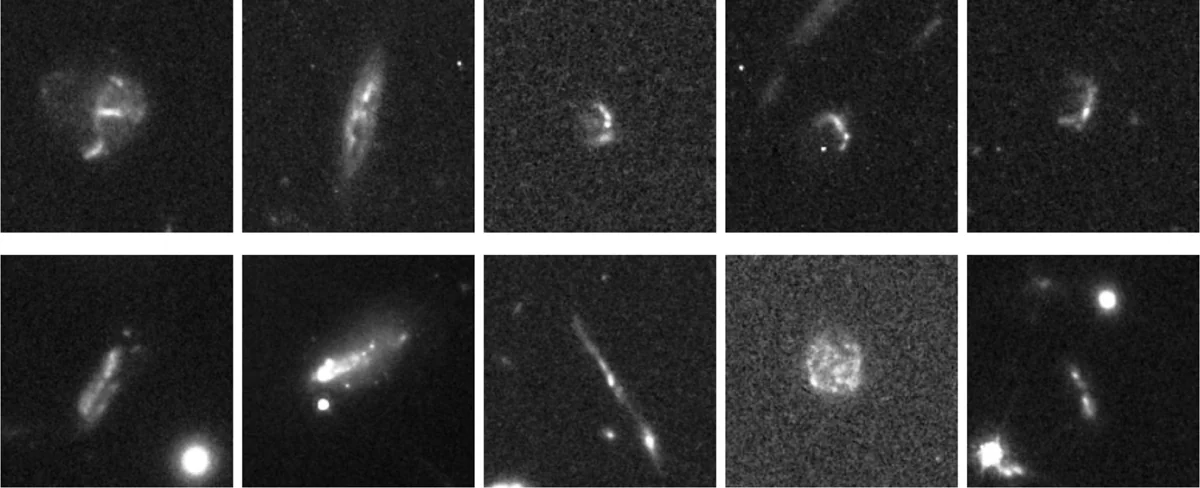
The 43 unclassifiable objects are still there, at known coordinates, now in a public catalogue. They might be galaxies of a class we have not predicted yet. More likely, some will turn out to be artefacts that slipped past the checks, and others familiar objects seen from an angle that makes them unrecognisable. To find out, somebody will have to point other telescopes at them.
References
O’Ryan, D. and Gómez, P. (2025), Identifying astrophysical anomalies in 99.6 million source cutouts from the Hubble legacy archive using AnomalyMatch, A&A, 704, A227. DOI: 10.1051/0004-6361/202555512
Code: AnomalyMatch on GitHub
Data catalogue: Zenodo, DOI 10.5281/zenodo.15298641