
Errori quasi zero, risultati sbagliati
Una rete neurale bayesiana impara a leggere i dati dell'Event Horizon Telescope. Sul banco di prova ottiene voti altissimi. Poi arrivano i dati veri.
Un programma che analizza dati e ti dice “non lo so” è più utile di uno che ti dà sempre una risposta. Sembra ovvio, ma le reti neurali convenzionali non lo fanno di default. Producono un numero: la rotazione del buco nero è 0,7. Punto. Nessuna barra di errore, nessuna sfumatura su quanto siano sicure. Se il dato è ambiguo, se due modelli fisici diversi producono segnali quasi identici, la rete sceglie comunque e non ti avvisa.
Il gruppo guidato da Janssen ha costruito un programma diverso, chiamato Zingularity, e lo ha pubblicato su Astronomy & Astrophysics. È una rete neurale bayesiana (BANN), un tipo di programma in cui i pesi interni, i numeri che la rete aggiusta durante l’addestramento, non sono valori fissi ma distribuzioni di probabilità. Ogni volta che la rete analizza un dato, produce non una risposta sola ma un ventaglio di risposte possibili, ciascuna con la propria probabilità. Se il dato è chiaro, il ventaglio è stretto. Se il dato è ambiguo, il ventaglio si allarga. E se il dato non somiglia a niente che la rete abbia mai visto, il ventaglio può spaccarsi in due picchi separati, un segnale esplicito che dice: qui non so scegliere.
L’obiettivo è ricavare le proprietà fisiche di due buchi neri supermassicci, oggetti così densi che nemmeno la luce riesce a sfuggire alla loro gravità, Sagittarius A* (Sgr A*) al centro della Via Lattea e Messier 87 (M87*), direttamente dai dati dell’Event Horizon Telescope (EHT), la rete di otto radiotelescopi che nel 2019 ha prodotto la prima immagine di un buco nero. Non dalle immagini ricostruite, ma dai dati grezzi: le misure di interferenza tra coppie di telescopi, chiamate visibilità, che contengono informazione sulla polarizzazione completa della luce.
135 milioni di parametri per cinque numeri
L’architettura di Zingularity combina due idee. La prima metà della rete è un blocco che riconosce schemi locali ripetuti nei dati (un’architettura chiamata ResNet). Le visibilità arrivano ordinate per coppia di telescopi e istante temporale, e la rete impara quali combinazioni di ampiezze e fasi, misurate su quali coppie di telescopi, sono più informative per ciascun parametro fisico. La seconda metà è la parte che rende la rete bayesiana: ogni neurone non ha un peso fisso ma una distribuzione, e a ogni ciclo di inferenza il peso viene estratto casualmente da quella distribuzione. Il risultato è che, data la stessa osservazione, la rete produce risposte leggermente diverse ogni volta. 100 passaggi danno 100 risposte, e la loro distribuzione è il posteriore: la stima della rete con annessa l’incertezza.
Per M87*, la rete ha 1 376 806 parametri liberi. Per Sgr A*, che richiede di stimare anche l’inclinazione del disco e l’angolo di posizione, ne ha 135 068 877. I numeri da ricavare sono tre o cinque: la rotazione del buco nero, lo stato magnetico del disco di materia (fortemente o debolmente magnetizzato), il rapporto tra la temperatura degli ioni e degli elettroni nel plasma. Per Sgr A* si aggiungono l’inclinazione del disco e l’angolo di posizione. La sproporzione è voluta. Una rete con molti più parametri di quanti ne debba stimare ha la libertà di trovare combinazioni complesse nei dati, pattern che un modello più piccolo perderebbe. La regolarizzazione, un meccanismo che penalizza i pesi troppo grandi o troppo numerosi, impedisce alla rete di memorizzare i dati invece di imparare da essi.
I dati di addestramento sono quelli della libreria sintetica che Janssen e colleghi hanno costruito nel primo paper della serie: 600 000 dataset per M87* e 252 000 per Sgr A*, ciascuno una simulazione completa del percorso del segnale dalla sorgente al telescopio, inclusi gli effetti atmosferici, gli errori di calibrazione e le contaminazioni tra canali di polarizzazione.
Il voto perfetto che non vale niente
Qui arriva il paradosso. Quando gli autori addestrano una versione della rete usando solo il rumore termico, la forma più semplice di disturbo nei dati, senza gli altri effetti di corruzione del segnale, gli errori di validazione crollano. La rete distingue quasi perfettamente tra modelli con campo magnetico forte e debole, stima la rotazione con errore minimo, classifica tutto con precisione.
Il risultato è inutile.
Una rete addestrata su dati troppo puliti impara a sfruttare caratteristiche del segnale che nei dati reali sono mascherate o distorte da effetti che il dato sintetico semplificato non conteneva. La turbolenza atmosferica, le variazioni di sensibilità dei telescopi, la contaminazione tra i canali di polarizzazione: tutto quello che la rete non ha mai visto diventa una fonte di errore sistematico invisibile. Il programma è sicuro delle sue risposte, perché le incertezze sono calibrate su un mondo più semplice di quello reale. La barra di errore è stretta. Attorno alla risposta sbagliata.
Gli autori lo dimostrano confrontando le curve di addestramento. Con i dati completi, la rete per M87* impiega 70 epoche, quella per Sgr A* 50 o 60 (un’epoca è un ciclo completo sull’intero set di addestramento), gli errori di validazione si stabilizzano su valori finiti e misurabili. Con i dati semplificati, gli errori scendono più velocemente e più in basso. La differenza non è un difetto della rete: è un difetto dei dati. Quando il set di addestramento non contiene tutta la complessità del mondo reale, il programma non ha modo di sapere che sta imparando una versione incompleta della realtà.
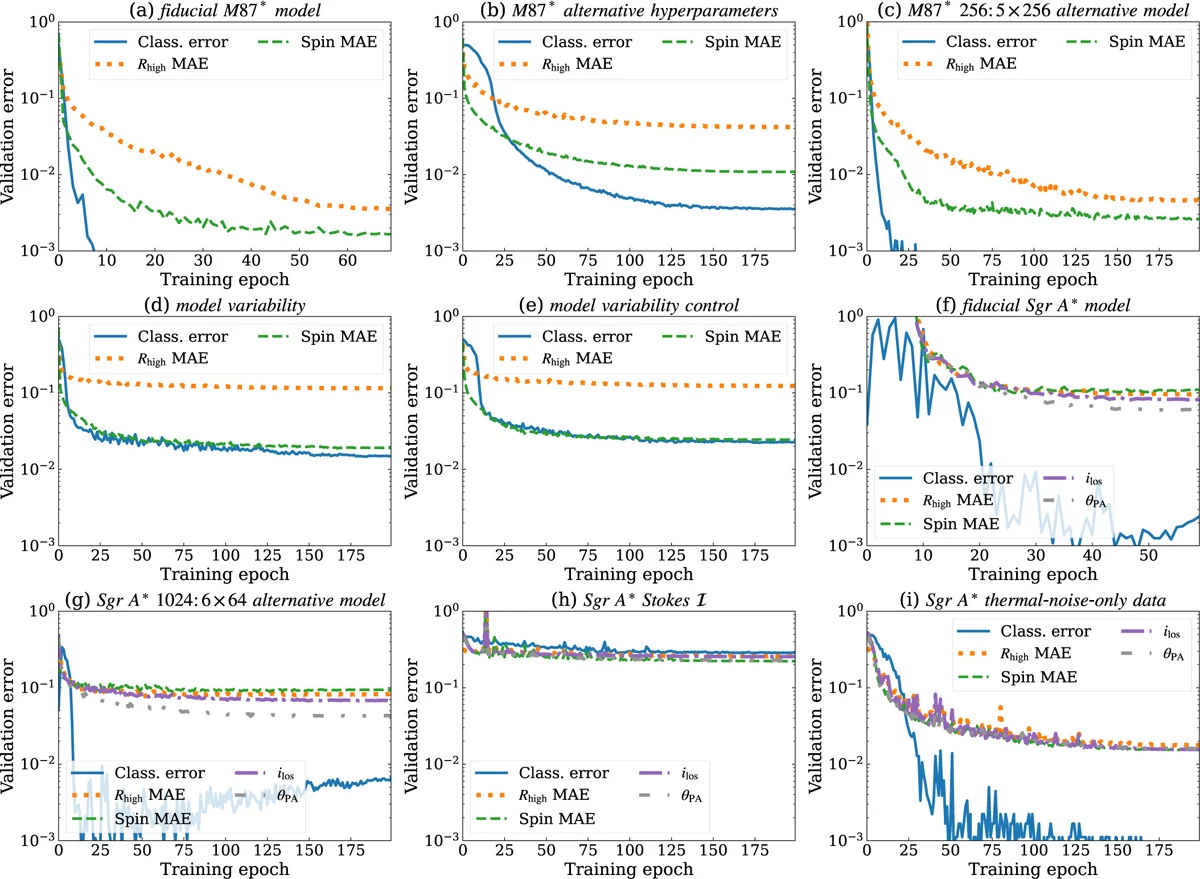
Quando la polarizzazione fa la differenza
La polarizzazione, la direzione in cui oscilla l’onda elettromagnetica, è il canale informativo che distingue Zingularity dai tentativi precedenti. Le analisi con reti neurali dell’EHT pubblicate finora usavano solo l’intensità totale della luce (il primo dei quattro parametri di Stokes, un insieme di grandezze che descrivono completamente lo stato di polarizzazione). Janssen e colleghi hanno incluso tutti e quattro i parametri di Stokes: l’intensità totale, la polarizzazione lineare in due direzioni, e la polarizzazione circolare. Otto canali di input in tutto, parti reali e immaginarie di ciascun prodotto di correlazione.
La differenza è netta soprattutto per la classificazione dello stato magnetico del disco. Senza la polarizzazione, i modelli di Sgr A* con campo forte e campo debole producono segnali in intensità che si somigliano. La rete addestrata solo sull’intensità totale fatica a distinguerli e gli errori di classificazione restano alti. Con la polarizzazione completa, la classificazione diventa quasi perfetta. Il campo magnetico forte lascia un’impronta nella polarizzazione lineare e circolare che è assente nei modelli con campo debole: la rete impara a riconoscerla.
Per la stima della rotazione del buco nero, l’effetto della polarizzazione è meno marcato, ma comunque presente. Il rapporto tra temperatura degli ioni e degli elettroni nel plasma, il parametro più difficile da stimare per i modelli di M87*, ha gli errori di validazione più alti indipendentemente dai dati usati. L’effetto di questo parametro sulle immagini è sottile: per i modelli con campo magnetico forte di M87*, il rapporto tra ioni ed elettroni cambia poco la morfologia dell’immagine, e quel poco è difficile da cogliere con la copertura dell’EHT del 2017.
Due codici, stesse equazioni, risposte diverse
La validazione più severa non viene dall’interno del dataset, ma dall’esterno. Gli autori hanno generato dati di test con un codice di simulazione diverso da quello usato per l’addestramento. I dati di addestramento vengono da KHARMA, i dati di test da BHAC-RAPTOR. Entrambi risolvono le equazioni della magnetoidrodinamica relativistica generale, le equazioni che descrivono come il plasma magnetizzato si muove vicino a un buco nero, ma con implementazioni numeriche diverse: diversi modi di tagliare la griglia di calcolo, diverse approssimazioni per il trasporto radiativo (il modo in cui la luce attraversa la materia lungo il percorso dalla sorgente al telescopio), diverse scelte per la temperatura degli elettroni.
Per M87*, il test è superato. La rete addestrata su KHARMA riconosce correttamente lo stato magnetico e stima la rotazione dei modelli BHAC-RAPTOR con errori piccoli. Il posteriore è stretto attorno al valore giusto. Le due simulazioni, pur essendo indipendenti, producono segnali sufficientemente simili sulle scale che la rete usa per decidere.
Per Sgr A*, il risultato è più interessante. Un modello con campo magnetico forte e organizzato (MAD), rotazione lievemente negativa e inclinazione intermedia viene identificato dalla rete come un modello con campo magnetico più debole e turbolento (SANE), rotazione fortemente negativa e inclinazione diversa. I parametri veri cadono tra i punti della griglia di addestramento: nessun modello nel set di addestramento ha esattamente quei valori. La rete, posta davanti a un segnale che non ha mai visto, lo associa al modello più simile che conosce. Il problema è che “più simile nei dati interferometrici” non significa “più simile nella fisica”. Due buchi neri con proprietà magnetiche opposte possono produrre visibilità quasi identiche attraverso gli otto telescopi dell’EHT, perché otto telescopi producono troppo poche coppie di misura per cogliere le differenze.
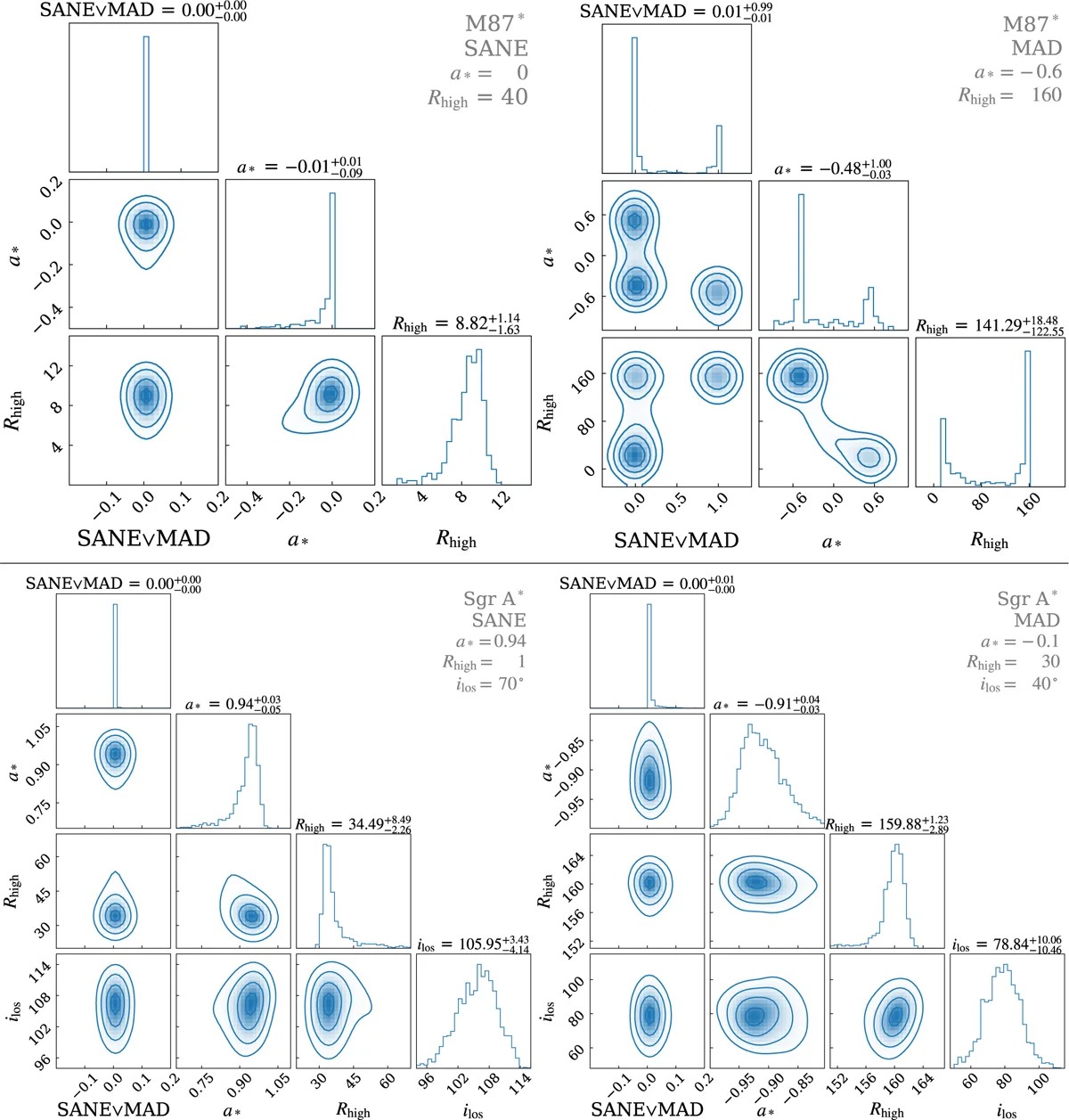
La natura bayesiana della rete, qui, funziona a metà. Il posteriore del modello identificato correttamente è stretto e centrato. Il posteriore del modello sbagliato è anch’esso stretto, ma centrato sul valore sbagliato. La rete non “sa” di non sapere, perché il segnale somiglia davvero a un modello nel set di addestramento. La modalità di fallimento onesta, quella in cui il posteriore si divide in due picchi segnalando ambiguità, compare solo quando il dato di test è un modello di M87* con parametri al limite della griglia: la rete vede due modelli ugualmente plausibili e lo dichiara. Per Sgr A*, la confusione è più insidiosa, perché il segnale interferometrico dei due modelli è troppo simile per essere distinto.
Il confronto tra simulazioni di codici diversi testa la dipendenza del metodo dalla scelta della simulazione, non la capacità di generalizzare ai dati reali dell’EHT. I dati reali contengono effetti aggiuntivi, tra cui la variabilità intrinseca di Sgr A* sulla scala temporale gravitazionale di circa 20 secondi, che nessuna delle simulazioni riproduce completamente.
Il programma più lento che batte tutti
Un aspetto sottovalutato di Zingularity è la velocità. L’addestramento è il pezzo costoso, ma una volta addestrata la rete, l’inferenza è quasi istantanea. Ottenere 100 posteriori da 100 ricampionamenti bootstrap dei dati dell’EHT richiede 20 secondi su una singola GPU. Il confronto con i metodi tradizionali usati dalla collaborazione EHT è impietoso: quelli richiedono di confrontare i dati osservati con centinaia di migliaia di modelli, uno alla volta, mediando su un sottinsieme degli effetti strumentali per isolare il segnale fisico. È un processo che richiede risorse computazionali molto maggiori e che, per ragioni di costo, spesso si limita a esplorare solo una parte dello spazio dei parametri.
Zingularity esplora lo spazio completo dei parametri dei modelli di magnetoidrodinamica e trasporto radiativo in un colpo solo. E lo fa tenendo conto, nel dato di addestramento, dell’intero percorso del segnale. L’alternativa tradizionale, per ottenere lo stesso risultato, sarebbe marginalizzare su tutti gli effetti strumentali per ogni modello, un calcolo che con i dati attuali sarebbe proibitivo.
La velocità ha un prezzo. La rete è legata ai modelli su cui è stata addestrata. Se il buco nero reale ha proprietà non previste dalla griglia di simulazioni (una composizione chimica diversa, effetti di riconnessione magnetica (la rottura improvvisa e il riassemblaggio delle linee di campo magnetico, che libera energia), un disco inclinato rispetto all’asse di rotazione), la rete non lo sa. Dà la risposta più vicina che conosce, con un’incertezza calibrata su un universo di possibilità che potrebbe non contenere quella giusta.
Lo spazio tra il voto e la realtà
Il paper si chiude affermando che è facile ottenere errori di validazione bassi su dati sintetici, soprattutto quando la modellizzazione dei dati è troppo semplificata. La frase vale ben oltre l’EHT. Ogni applicazione di machine learning a dati scientifici reali si scontra con lo stesso problema: il dato sintetico di addestramento è un modello della realtà, e ogni modello ha dei limiti. La differenza tra un buon programma e uno pericoloso sta nella capacità di segnalare quando quei limiti sono stati raggiunti.
Zingularity lo fa in due modi: attraverso i posteriori bayesiani, che si allargano o si spezzano quando il dato è ambiguo, e attraverso il bootstrap, un ricampionamento dei dati osservati che propaga le incertezze strumentali fino alla risposta finale. Nessuno dei due meccanismi è perfetto. Il posteriore stretto attorno alla risposta sbagliata, come nel caso del modello Sgr A* identificato erroneamente, mostra che la rete può fallire in silenzio quando il dato somiglia troppo a qualcosa di diverso. L’applicazione di queste reti ai dati reali dell’EHT, con i risultati sulle proprietà fisiche dei due buchi neri, è il contenuto del terzo paper della serie, pubblicato insieme a questo su Astronomy & Astrophysics.
I 135 milioni di parametri della rete per Sgr A* convergono su cinque numeri. La domanda aperta è se quei cinque numeri descrivano il buco nero che c’è, o il buco nero più simile tra quelli che la rete ha imparato a riconoscere.
Riferimenti
Janssen, M. et al. (2025), Deep learning inference with the Event Horizon Telescope. II. The ZINGULARITY framework for Bayesian artificial neural networks, A&A, 698, A61. DOI: 10.1051/0004-6361/202553785
Codice: Zingularity su GitLab