
La rete cercava una cosa, ne ha trovate mille altre
Hubble è in orbita da oltre 30 anni e ha accumulato 100 milioni di immagini che nessuno ha mai guardato bene. Una rete neurale ci ha messo due giorni e mezzo, e quello che ha trovato non era quello che cercava.
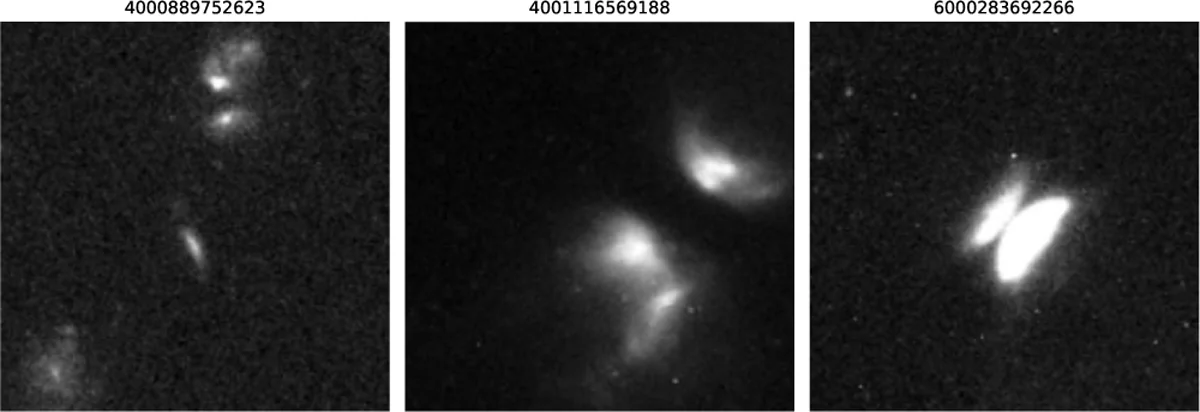
Esistono nell’archivio del telescopio spaziale Hubble (HST, dall’inglese Hubble Space Telescope) 43 oggetti che nessuno sa cosa siano. Sono lì dentro da anni, alcuni da decenni. Hanno una forma che non rientra in nessuna categoria conosciuta. Potrebbero non essere galassie. Potrebbero non essere niente di quello che gli astronomi sanno descrivere. Sono stati scovati a fine 2025 da una rete neurale che, peraltro, stava cercando una cosa completamente diversa.
L’archivio di Hubble contiene quasi 100 milioni di immagini di sorgenti astronomiche. Oltre 30 anni di osservazioni, raccolte una alla volta da astronomi che chiedevano tempo al telescopio per studiare un oggetto specifico. Quando l’osservazione veniva completata, il bersaglio finiva sotto i riflettori. Tutto il resto, lo sfondo, finiva nell’archivio e ci restava. Questo paper di O’Ryan e Gómez, pubblicato su Astronomy & Astrophysics, racconta cosa succede quando provi a guardare quel resto, sistematicamente, con un programma. La storia è soprattutto su come la rete neurale si comporta quando le chiedi di trovare “qualcosa di strano” senza specificare troppo cosa significhi.
Il problema di insegnare a una rete cosa è raro
Una rete neurale impara dagli esempi. Le mostri mille foto di gatti e mille di cani, e dopo un po’ distingue i due. Funziona finché di esempi ne hai a bizzeffe.
In astronomia spesso non li hai. Gli oggetti rari sono rari per definizione: una lente gravitazionale, un disco protoplanetario visto di taglio, una galassia medusa che si lascia dietro un velo di gas. Di alcuni di questi se ne conoscono qualche centinaio in tutto. Provare ad addestrare un programma con così pochi esempi non funziona: la rete impara a memoria gli oggetti che le hai mostrato e fallisce su qualunque variante.
C’è anche un problema più sottile. Per insegnare a una rete cosa è anomalo, dovresti definire prima cosa è normale. Ma “normale” nell’archivio di Hubble è un concetto sfuggente. Le immagini sono sgranate, sovraesposte, piene di stelle in primo piano, satelliti di passaggio, raggi cosmici. Una galassia comune convive con artefatti che a un occhio inesperto sembrano già interessanti.
O’Ryan e Gómez hanno usato un approccio chiamato apprendimento semi-supervisionato (semi-supervised learning), un termine che descrive una situazione precisa: hai pochissimi esempi etichettati a mano e una marea di dati senza etichetta. Lo strumento, AnomalyMatch, è una rete che impara su entrambi contemporaneamente: sui pochi esempi etichettati impara cosa cercare, sulla marea senza etichetta impara cosa è ordinario. Più una variante chiamata apprendimento attivo (active learning): la rete propone i suoi candidati migliori, l’autore guarda, conferma o smentisce, e il modello si aggiorna. Un dialogo tra programma e umano, in cui l’umano fa il lavoro che la rete non sa fare e la rete fa il lavoro che l’umano non avrebbe il tempo di fare.
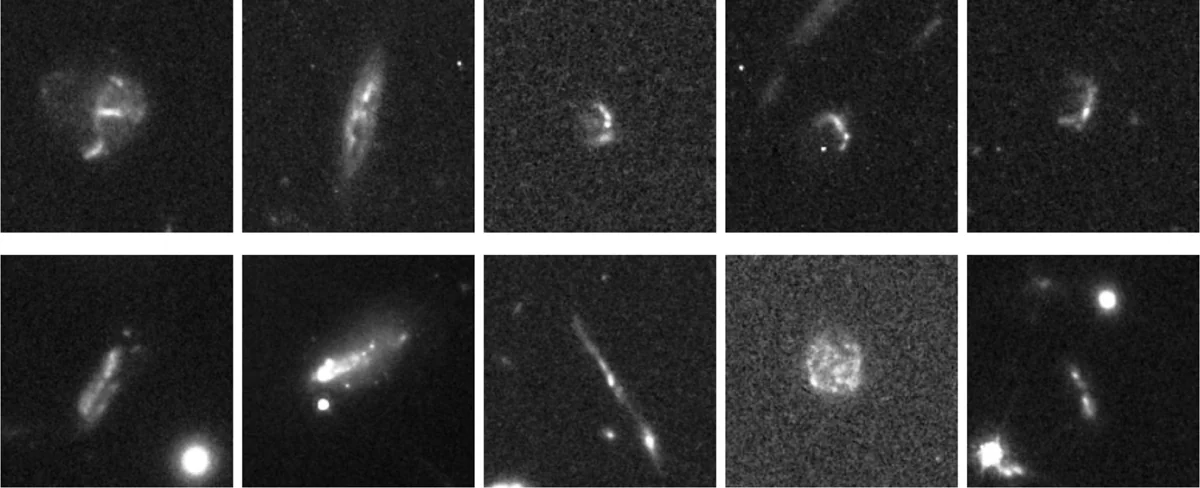
Il punto di partenza era ridicolmente piccolo. Tre immagini di addestramento (in gergo, il training set: l’insieme di dati su cui la rete si fa l’occhio). Tre. Tutte di dischi protoplanetari, ovvero stelle giovani circondate da un anello di polvere e gas dove si stanno formando i pianeti, viste perfettamente di taglio. La prospettiva produce una forma a farfalla molto distintiva: una striscia scura di polvere al centro, e ai lati la luce che fuoriesce in due lobi perpendicolari. O’Ryan voleva trovarne altri. Erano l’oggetto della sua tesi.
Quello che la rete ha trovato cercando altro
Tre immagini di addestramento, 99,6 milioni di ritagli da analizzare. AnomalyMatch è girato su ESA Datalabs, la piattaforma scientifica dell’Agenzia Spaziale Europea, per due giorni e mezzo, su un cluster di schede grafiche dedicate al calcolo parallelo (GPU, l’hardware che le reti neurali usano oggi al posto della CPU per macinare conti su molti dati alla volta).
Il risultato è una lista di 5 000 candidati ordinati per “punteggio di anomalia”, un numero tra 0 e 1 che dice quanto la rete trova quell’immagine fuori dall’ordinario. Dopo aver eliminato i duplicati (lo stesso oggetto è spesso ripreso più volte da Hubble, con leggeri spostamenti) restano 1 339 oggetti unici.
Di dischi protoplanetari di taglio, quelli che cercavano, ne sono saltati fuori solo due. La ragione è una nota a margine ma dice molto: l’archivio analizzato era stato selezionato in un singolo filtro, una banda specifica di lunghezze d’onda della luce. I dischi protoplanetari di taglio si vedono meglio in altre bande, e la maggior parte di quelli noti agli astronomi è stata osservata altrove. La rete cercava nel posto sbagliato.
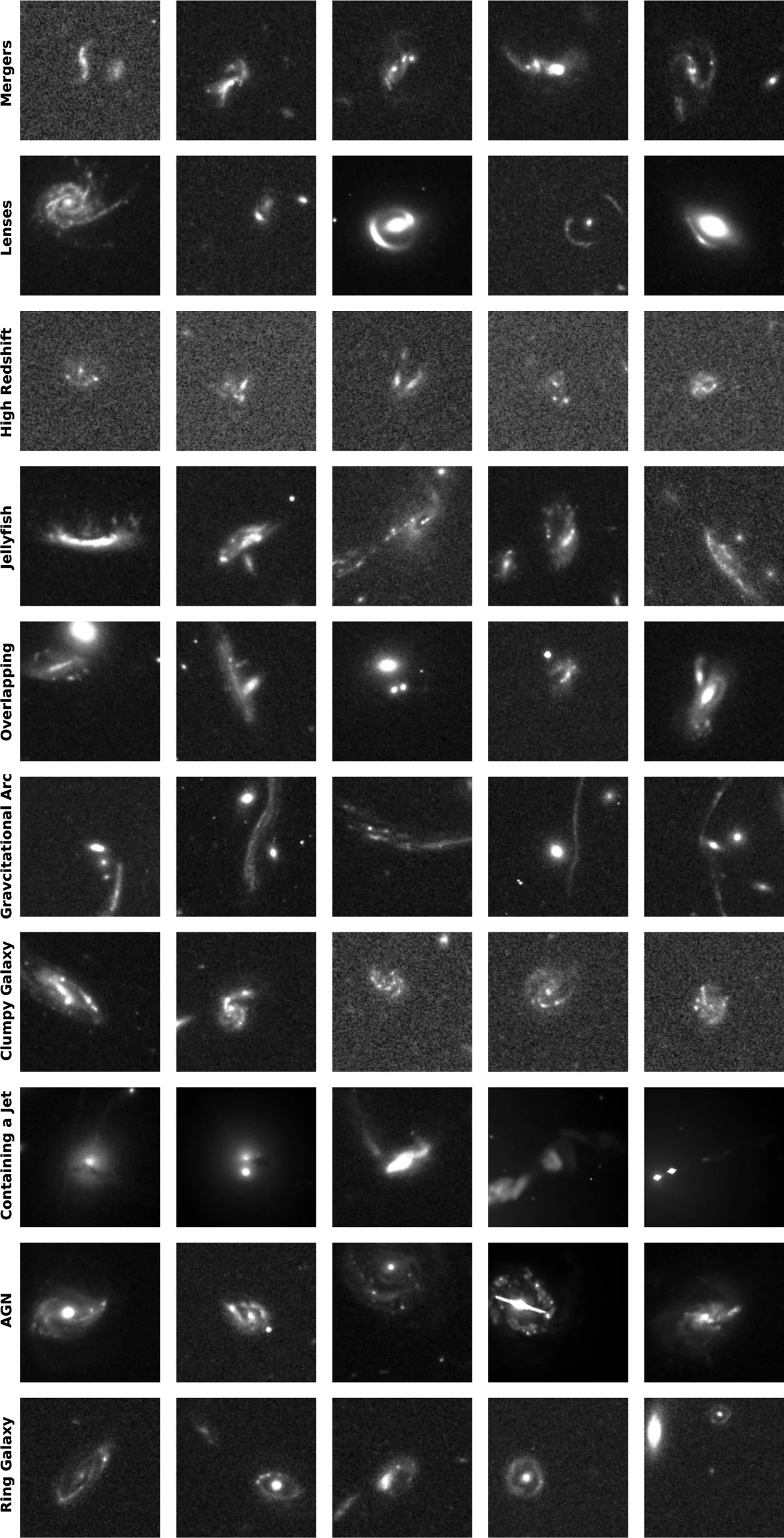
Quello che ha trovato altrove è la parte interessante. Più della metà del campione (629 oggetti) sono coppie di galassie che si stanno scontrando, fusioni galattiche colte nell’atto di passarsi attraverso. Poi ci sono 140 candidati lente gravitazionale, dove la luce di una galassia molto lontana, viaggiando verso di noi, è stata deformata dalla gravità di una galassia interposta in un arco luminoso o in un anello: di queste, oltre la metà non risultava in nessun catalogo precedente. E 35 galassie medusa, oggetti che mentre attraversano un ammasso vengono spogliate del proprio gas dalla pressione del mezzo intergalattico e si lasciano dietro una scia di tentacoli luminosi.
Il numero che fa la storia è un altro: 811 oggetti su 1 339 non risultavano in nessun lavoro precedente. 65 per cento. Una rete partita con tre esempi ha individuato, in due giorni e mezzo, 800 oggetti che si trovavano nell’archivio di uno dei telescopi più studiati della storia e che nessuno aveva mai descritto.
Quando la rete impara cosa non sa di sapere
Il dettaglio più interessante del paper non è quanti oggetti la rete abbia trovato, ma cosa ha trovato senza che nessuno glielo avesse insegnato a cercare. Tra le 1 339 anomalie ci sono cinque quasar lensati. Un quasar è il nucleo brillantissimo di una galassia molto lontana, alimentato da un buco nero che divora gas. Quando la sua luce, viaggiando verso di noi, viene deformata dalla gravità di una galassia interposta, lo chiamiamo quasar lensato. L’effetto produce un’immagine caratteristica: quattro punti luminosi disposti in croce attorno alla galassia centrale, oppure due punti specchiati. Si chiama croce di Einstein quando i punti sono quattro. Sono oggetti rarissimi, se ne conoscono meno di 200 in tutto il cielo.
AnomalyMatch ne ha trovati cinque. Tutti già noti agli astronomi, è vero, ma c’è un dettaglio che cambia tutto: nel training set non c’erano quasar lensati. Nemmeno uno. La rete è stata addestrata su dischi protoplanetari, su galassie strane, su fusioni e su qualche lente classica. Un quasar lensato è comparso spontaneamente tra i candidati a punteggio più alto. Gli autori, a quel punto, ne hanno aggiunto un esempio al training, e la rete ne ha tirato fuori altri quattro. Cinque in tutto.
La rete aveva imparato un concetto più astratto, qualcosa come “questa immagine è strana”, abbastanza solido da catturare una classe di oggetti di cui non aveva mai visto un solo esempio. È quel tipo di generalizzazione che rende le reti neurali utili al di fuori dei compiti per cui le hai programmate, e che al tempo stesso rende difficile capire cosa stiano effettivamente facendo.
Gli autori hanno provato a guardare dentro la scatola con un metodo chiamato SHAP, un sistema che produce mappe di calore: pixel rossi dove il programma si è basato di più per dare il punteggio, pixel blu dove ha guardato meno. Sulle lenti, il rosso si concentra sull’arco gravitazionale. Sulle fusioni, sulle code mareali, cioè i ponti di stelle e gas che le due galassie si tirano l’una verso l’altra. Sui dischi visti di taglio, sulla forma a farfalla. Funziona come ci si aspetta. Sulla croce di Einstein, queste mappe non sono riportate, e il fatto stesso che la rete abbia pescato un oggetto fuori distribuzione lascia un margine di mistero su cosa abbia esattamente visto.
I limiti che la rete non poteva aggirare
AnomalyMatch ha generato 5 000 candidati. Quei 5 000 candidati li ha guardati uno per uno una persona sola: David O’Ryan, il primo autore, classificandoli a mano sulla base della morfologia e cercando ciascun oggetto nei cataloghi astronomici esistenti.
È il limite strutturale di questo tipo di lavoro. La rete dà un ranking, non una scoperta. Per trasformare un ranking in una scoperta serve qualcuno che ogni candidato lo verifichi, lo confronti con la letteratura, e decida cosa sia. In questo caso quel qualcuno era una persona. Nei prossimi anni, con la missione Euclid (un telescopio spaziale europeo lanciato nel 2023 per mappare miliardi di galassie) che sforna terabyte di dati ogni notte, e con l’osservatorio Vera C. Rubin appena entrato in funzione, che fotografa l’intero cielo australe ogni circa tre notti, il collo di bottiglia non sarà la rete. Sarà l’umano che dovrà guardare quello che la rete ha selezionato. Il tasso di contaminazione di AnomalyMatch, ovvero la frazione di immagini segnate come anomale che a un occhio esperto sono normali, è circa il 10 per cento. Filtrarle richiede esattamente l’occhio addestrato che si voleva alleggerire dal lavoro.
Poi c’è una cosa che con le reti neurali non c’entra niente, e racconta da sola perché questi paper sono interessanti. Gli autori notano che le galassie medusa potrebbero essere state difficili da pescare. La ragione non è astronomica e nemmeno algoritmica: è che le immagini dell’archivio di Hubble erano state salvate come JPEG a un canale di grigio, un formato che comprime aggressivamente i dati a bassa luminosità per risparmiare spazio. I tentacoli delle galassie medusa, fatti di gas tenue strappato dalla galassia ospite, vivono esattamente in quelle zone di bassa luminosità. Più che un limite della rete, è un limite del materiale: un compromesso sulla compressione fatto chissà quando può aver cancellato in partenza proprio le strutture che avrebbero reso riconoscibili quegli oggetti. 30 anni di dati astronomici, e il limite di quello che oggi possiamo trovarci dentro è in parte determinato da una scelta di formato file che nessuno pensava sarebbe diventata limitante.
100 milioni di immagini, e ricominciare
65 per cento di oggetti senza letteratura associata, in un archivio che gli astronomi consultano da decenni, è una cifra che dice qualcosa di scomodo. Non sul telescopio, che ha fatto il suo lavoro. Sulla nostra capacità di guardare quello che abbiamo già. Le osservazioni astronomiche sono quasi sempre fatte chiedendo tempo al telescopio per puntare un oggetto specifico. Quello che si trova nello stesso campo di vista, accanto al bersaglio, raramente viene esaminato. E così le scoperte si accumulano nell’archivio in attesa di un metodo per pescarle fuori.
AnomalyMatch è una versione di quel metodo, ne hanno proposti molti negli anni. Quello che rende questo paper notevole è la combinazione di scala (l’intero archivio, non un sottoinsieme), velocità (due giorni e mezzo) ed efficienza nei dati di addestramento (poche centinaia di etichette in tutto). Non è una rete spettacolare dal punto di vista architetturale. È un EfficientNet, una rete neurale convoluzionale: piccoli filtri che scorrono sull’immagine e si attivano dove trovano forme locali, prima bordi e texture, poi strutture via via più complesse. Sopra c’è il trucco semi-supervisionato. Il punto non è quanto sofisticata sia la rete: è che funziona abbastanza bene da rendere praticabile una cosa che prima non lo era.
I 43 oggetti inclassificabili continuano a essere lì, a coordinate note, ora in un catalogo pubblico. Potrebbero essere galassie di una classe che non abbiamo ancora previsto. Più probabilmente, alcuni saranno artefatti che hanno superato i controlli, e altri saranno oggetti familiari visti da un’angolazione che li rende irriconoscibili. Per saperlo, qualcuno dovrà puntarci sopra altri telescopi.
Riferimenti
O’Ryan, D. e Gómez, P. (2025), Identifying astrophysical anomalies in 99.6 million source cutouts from the Hubble legacy archive using AnomalyMatch, A&A, 704, A227. DOI: 10.1051/0004-6361/202555512
Codice: AnomalyMatch su GitHub
Catalogo dati: Zenodo, DOI 10.5281/zenodo.15298641